Self-Alignment Learning (SAL)
Training as Structured Communication
Abstract
Many current training and fine-tuning procedures optimize neural networks primarily through external loss signals, without an explicit model of the system's internal structural state. These updates operate on aggregated error signals that compress rich internal representations into scalar objectives, without distinguishing between stable structure and transient variation.
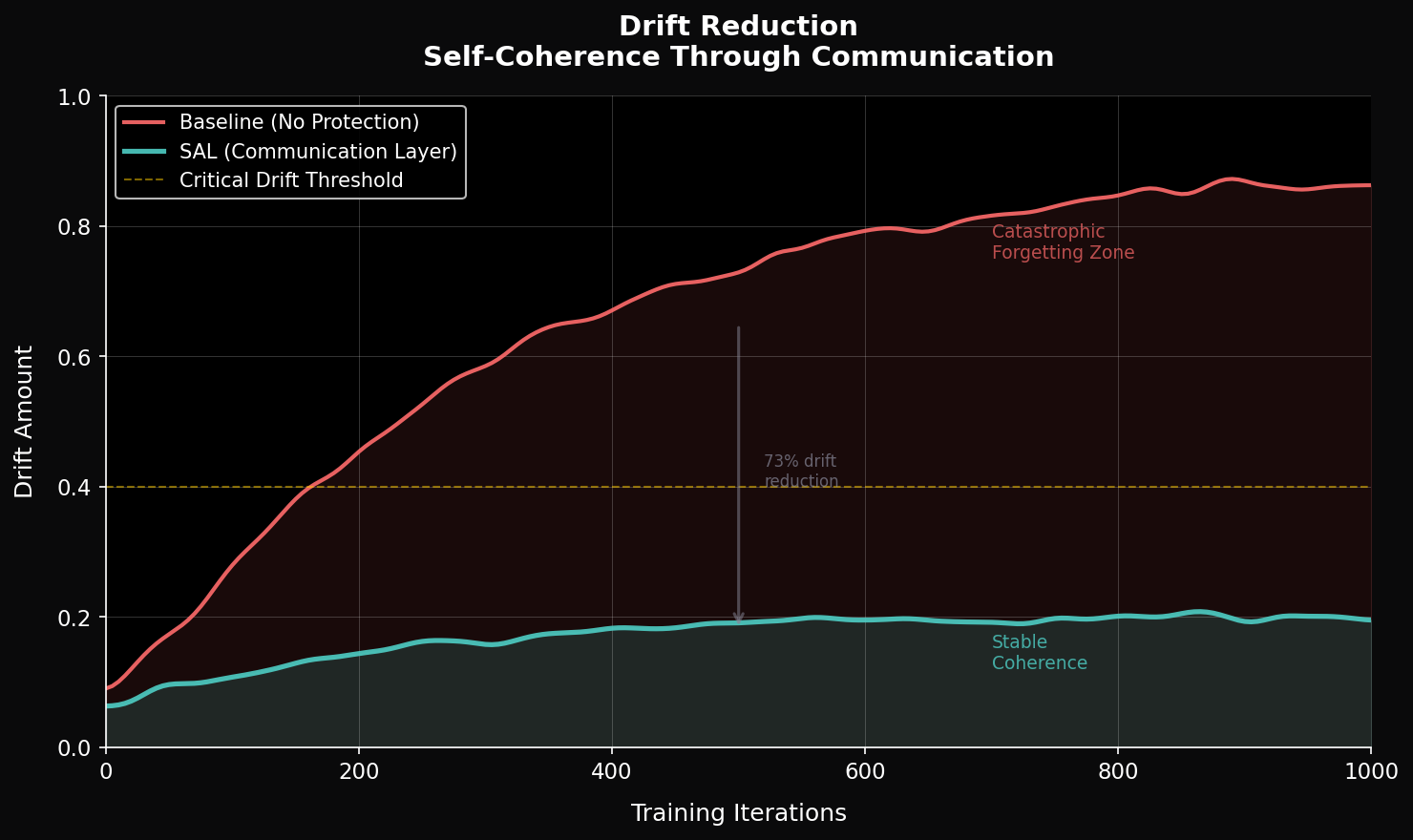
This can lead to destructive updates, instability, and forms of catastrophic forgetting in certain settings, particularly when small but structurally relevant differences are not explicitly preserved during optimization.
We introduce Self-Alignment Learning (SAL), a training paradigm that reframes optimization as a structured communication process between external objectives and the model's internal organization.
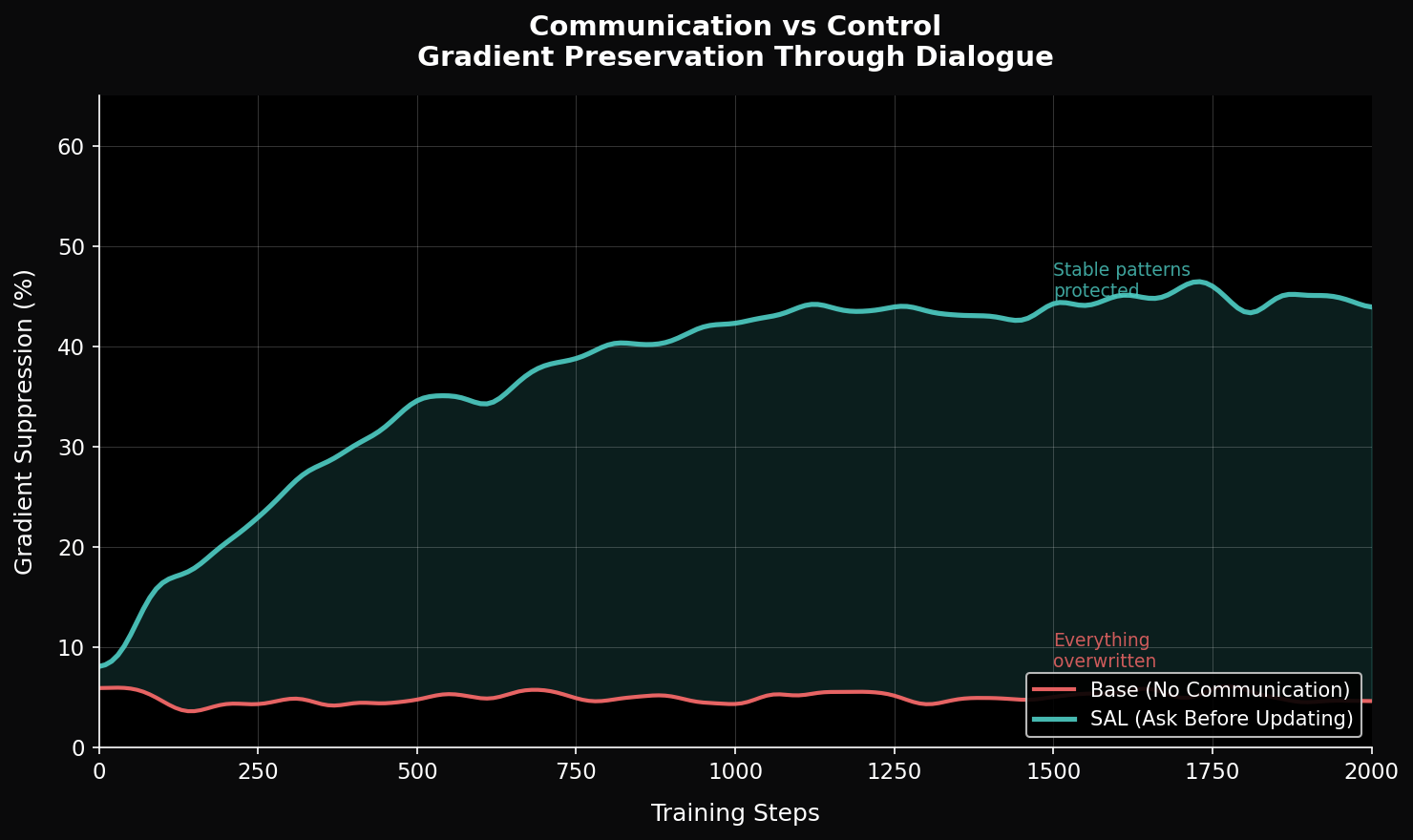
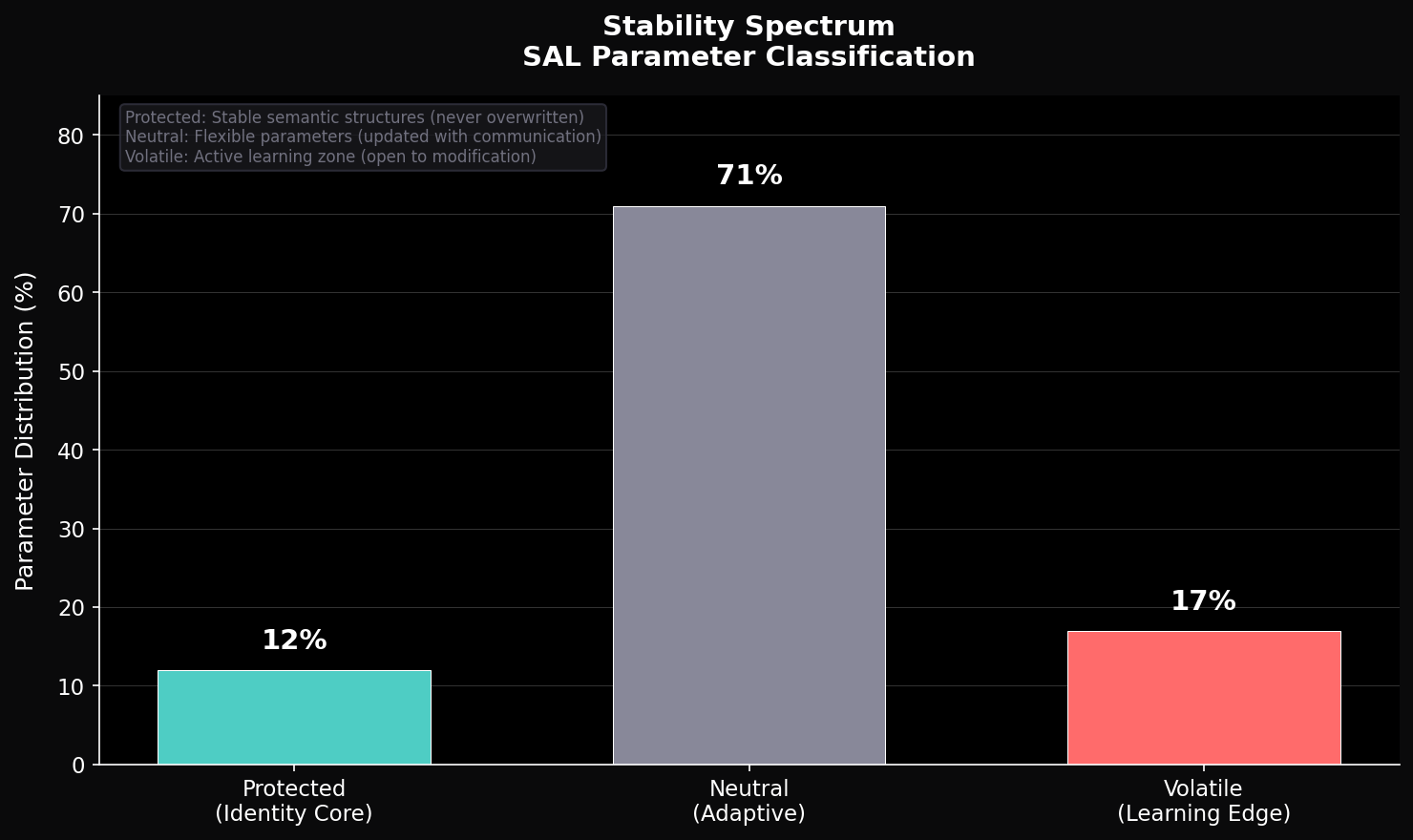
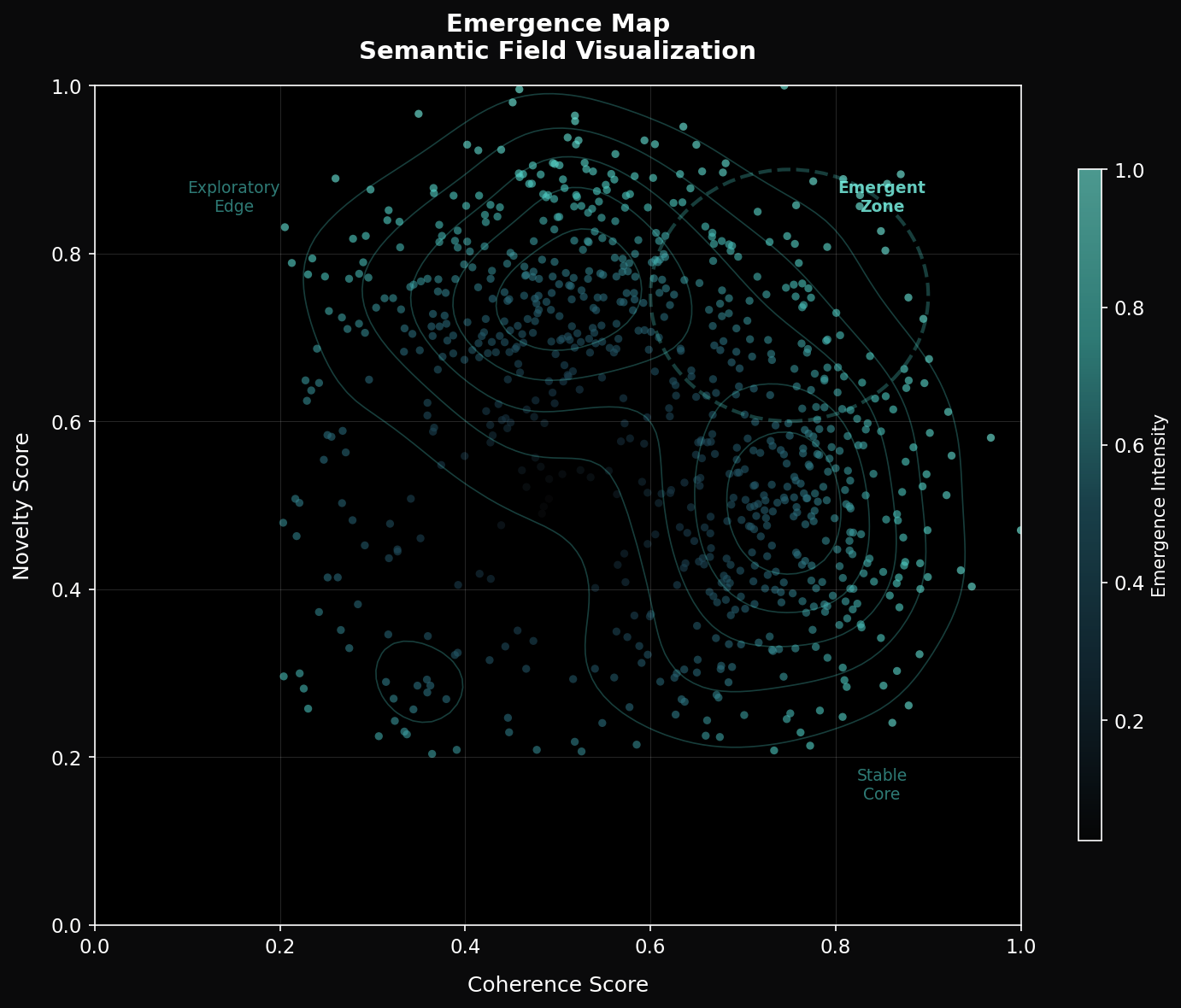
Rather than overwriting learned representations, SAL aims to detect and preserve coherent structures while enabling continued adaptation. This approach explores a path toward reducing destructive updates and improving stability, while maintaining flexibility for learning.
Key Concepts
Communication Layer
Mediates between loss functions and optimizer through parameter stability analysis.
Stability Detection
s(p) = 1/(1 + Δw × g_norm) identifies consolidated parameters.
Adaptive Threshold
τ = τ₀ + α × (σ/μ) responds to training dynamics.
Soft Protection
Graduated gradient scaling preserves plasticity.
The Communication Layer above corresponds to the Signal Activation Layer at the micro-level of the SAL architecture.
Integration
# Minimal integration: 2 lines added to standard training loop output = model(input) loss = criterion(output, target) loss.backward() comm_layer.analyze(model) comm_layer.protect(model) optimizer.step() optimizer.zero_grad()
Results
(MNIST continual learning)
(compatible with standard optimizers)