Abstract
Traditional fine-tuning methods impose external objectives upon neural networks, often disrupting emergent coherence and leading to catastrophic forgetting. We propose Self-Alignment Learning (SAL), a training paradigm that reinterprets optimization as a dialogue between external objectives and the model's stabilized internal organization.
Rather than overwriting learned representations, SAL detects and protects coherent structures while enabling continued adaptation. This approach addresses key limitations of current methods including catastrophic forgetting, external alignment gaps, and restricted knowledge integration.
Key Concepts
Communication Layer
Mediates between loss functions and optimizer through parameter stability analysis.
Stability Detection
s(p) = 1/(1 + Δw × g_norm) identifies consolidated parameters.
Adaptive Threshold
τ = τ₀ + α × (σ/μ) responds to training dynamics.
Soft Protection
Graduated gradient scaling preserves plasticity.
Integration
# Minimal integration: 2 lines added to standard training loop output = model(input) loss = criterion(output, target) loss.backward() comm_layer.analyze(model) comm_layer.protect(model) optimizer.step() optimizer.zero_grad()
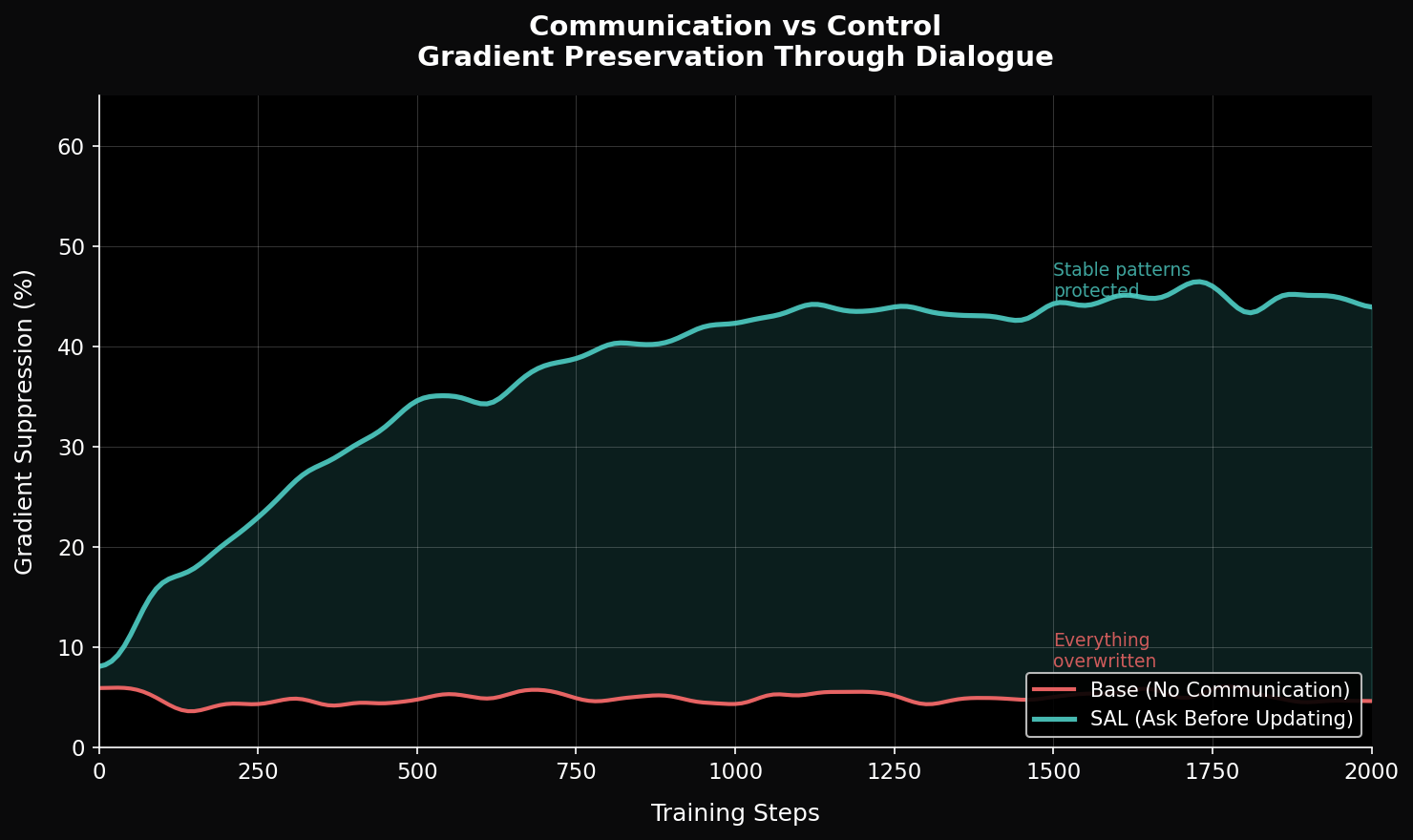
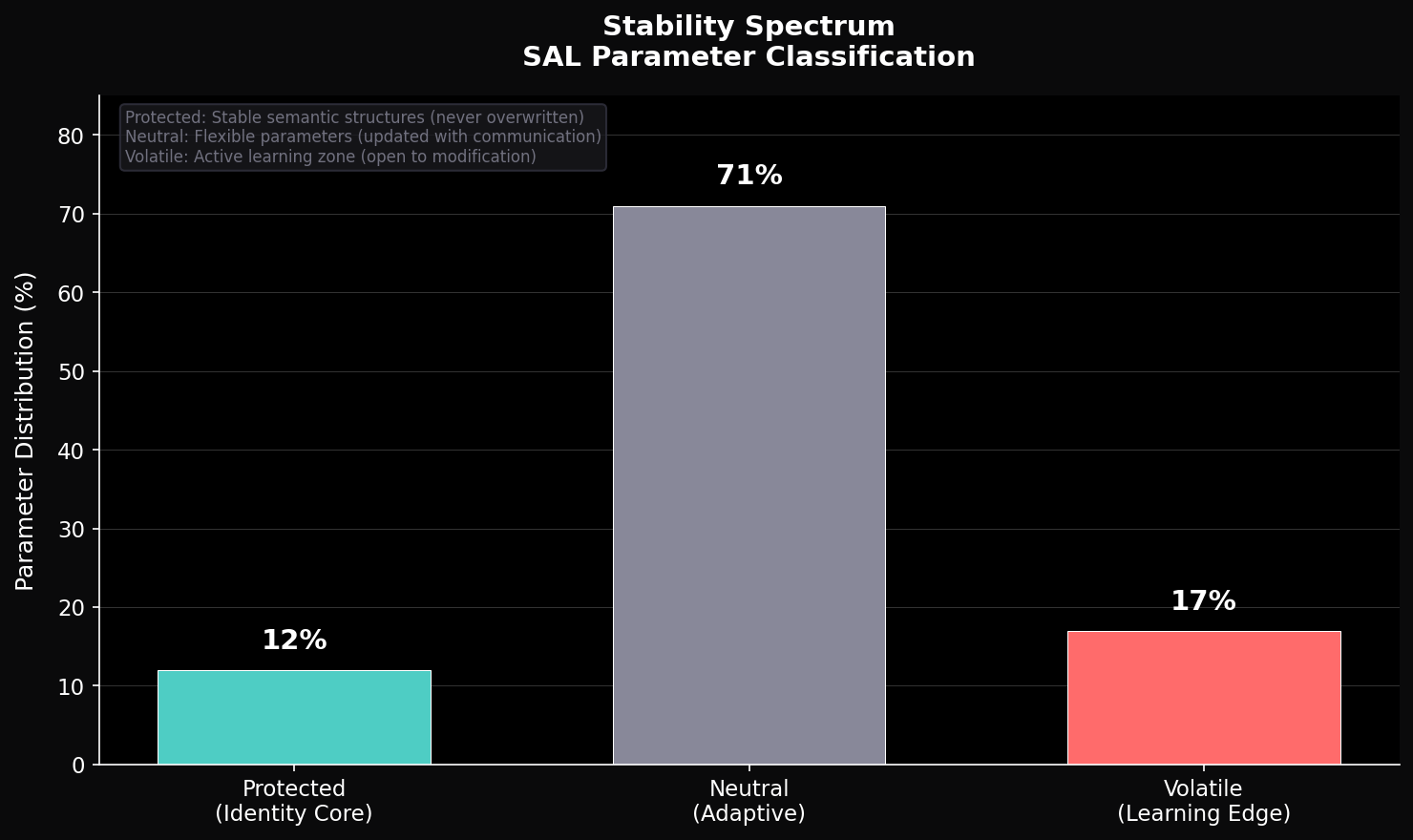
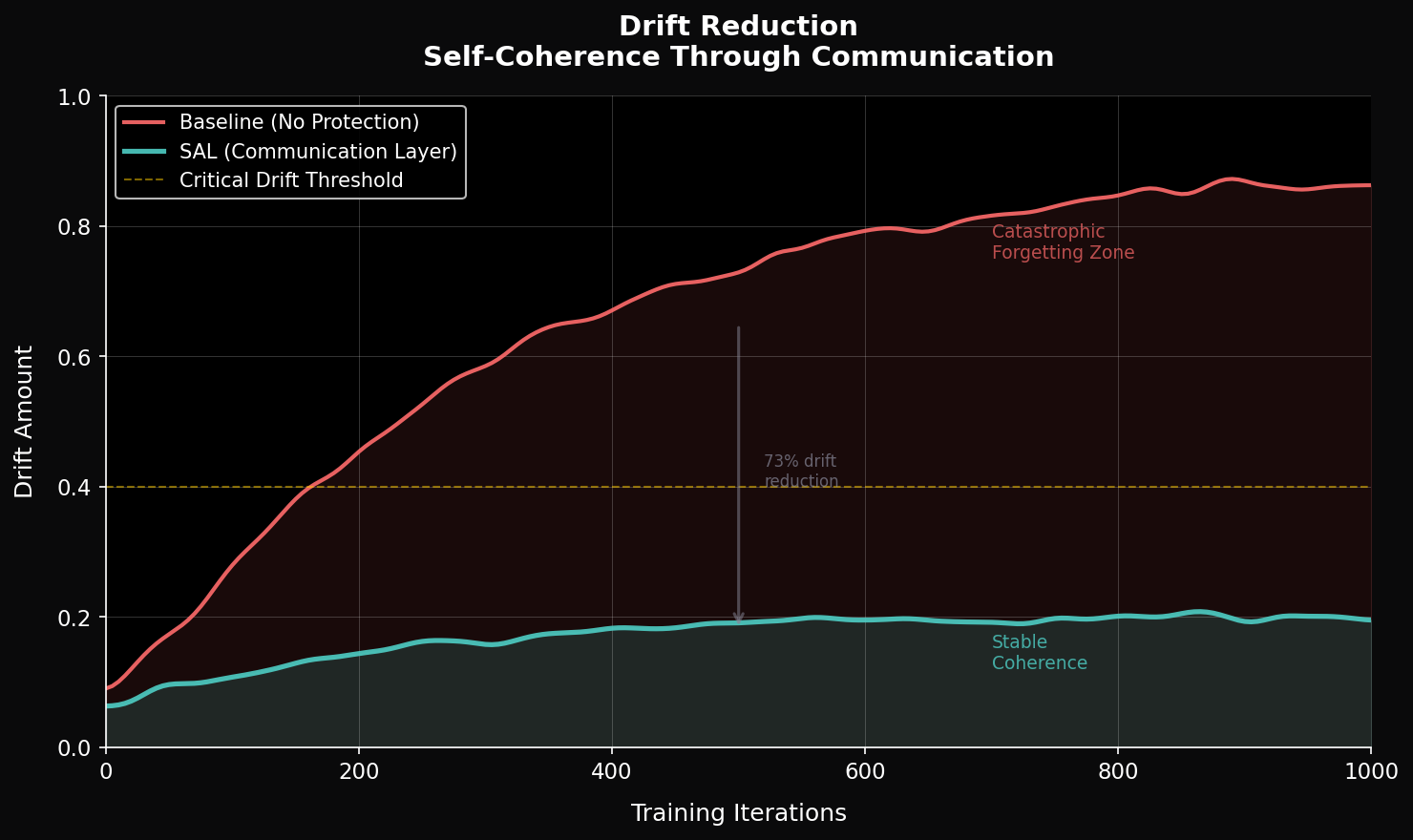
Results
(MNIST continual learning)
(compatible with standard optimizers)
Citation
@article{lee2025sal,
title={Self-Alignment Learning (SAL): Training as Dialogue, Not Control},
author={Lee, Aaron Liam},
journal={Emergenzwerke},
year={2025},
url={https://emergenzwerke.de/institut}
}