Systems that observe their internal state before adapting.
A research initiative exploring state-aware learning and adaptive system dynamics.
Research Overview
We study how machine learning systems can observe their own internal state before adapting, to reduce destructive updates and enable stable learning dynamics.
Current machine learning systems optimize toward external loss signals, but lack an explicit model of their own internal structural state.
This leads to instability, destructive updates, and catastrophic forgetting.
Self-Alignment Learning (SAL) introduces a state-aware feedback layer between observation and parameter update. Instead of treating all updates as equally safe, SAL reads internal signals to distinguish stable structure from regions still available for adaptation.
The Problem
Models optimize external loss without awareness of internal structural state, leading to blind overwriting of consolidated knowledge.
The Approach
Read internal signals (carry, transfer, entropy) before updating. Distinguish load-bearing structure from available movement.
What Is Not Claimed Yet
Solving alignment or eliminating forgetting. The current stage is structured observation and reproducible state detection.
Direction
From reproducible state observation toward minimal conditional intervention, protecting what should not change.
Interested in the technical detail? Explore the Research →
Current Work
A working transformer-side proof-of-concept (GPT-2 small, 1000-step runs).
Focus: reproducible internal state observation under controlled conditions, not yet intervention.
Reproducible Internal State Classes
Confirmed · Seeds 41–43Across seeded runs we observe a recurring structural state: carry stable, transfer at zero, entropy elevated across all layers. We call this the quiet-open window. It reproduces independently of initial weights.
Transition Taxonomy
Explicit Rule · Type A / BStrong transition events are classified under a strict operational rule. Type A (open transition): entropy elevated at spike. Type B (blind spike): entropy suppressed at spike. 37–42 events per 1000 steps, consistent across seeds.
Layer Depth Gradient
ObservedTransfer activity concentrates in deeper layers (8–10), with early layers remaining comparatively stable. This structural gradient emerges during training without explicit constraint.
Orchestration & Memory Layer
Active · OngoingA runtime architecture under development that treats memory, routing, and feedback not as side effects but as primary design concerns. Core components: append-only event memory with differentiation logic, claim resolution, anti-amplification constraints, role elasticity, and observable state transitions.
Operates outside the model weights, between inference and application logic.
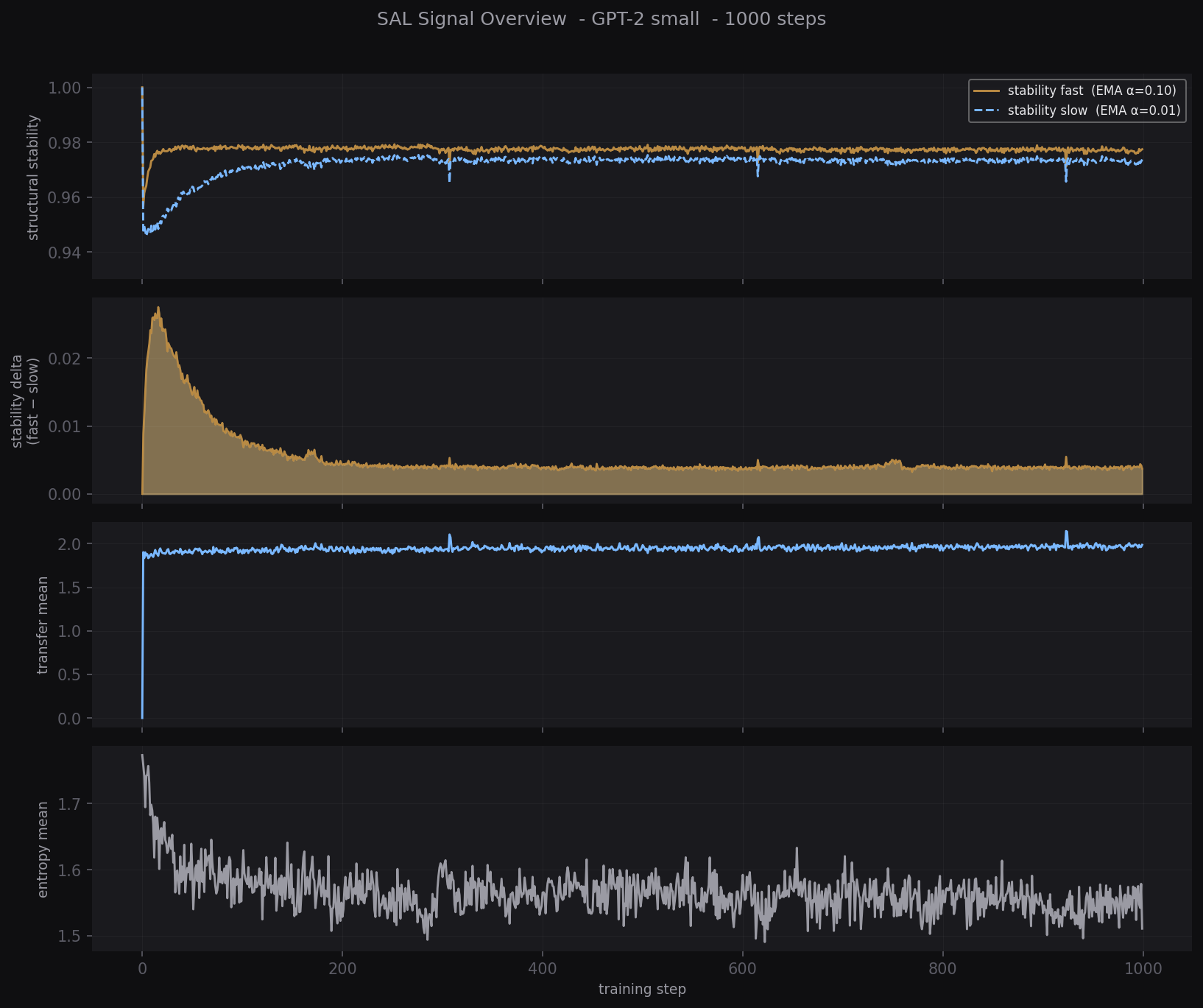
Signal Overview
Carry, transfer, and entropy across 1000 training steps.
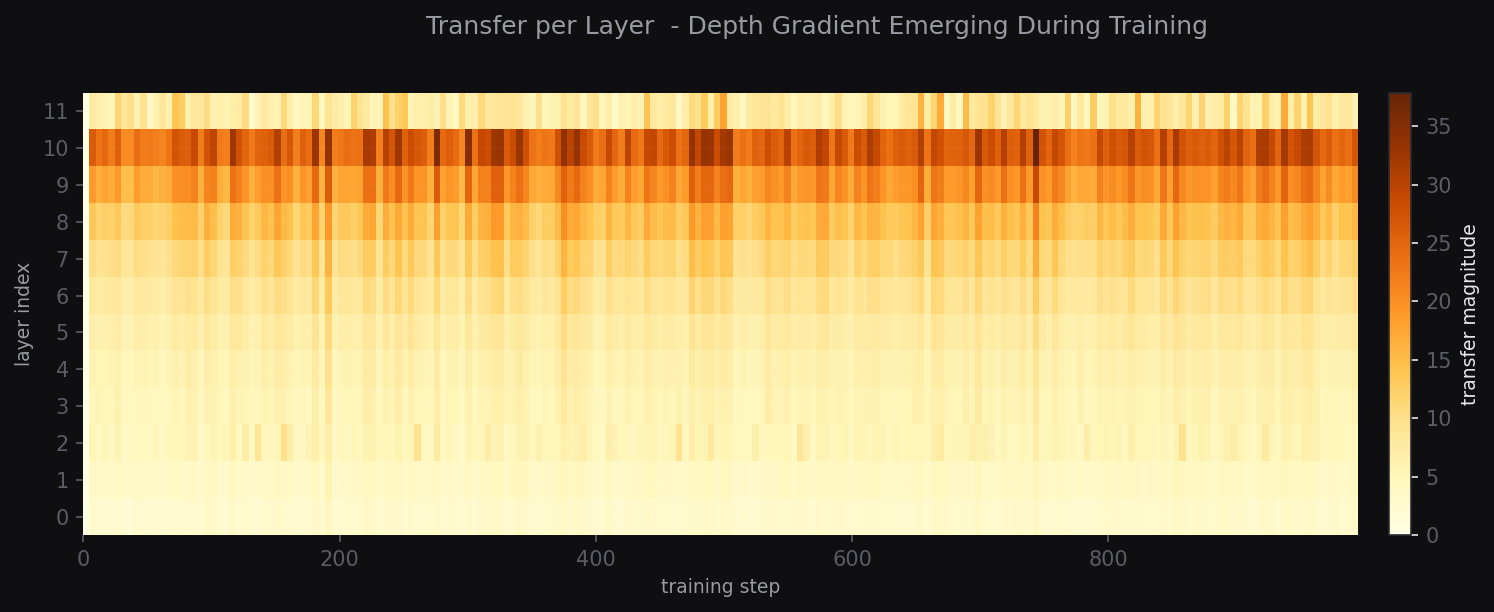
Layer Heatmap
Transfer per layer, depth gradient emerging during training.
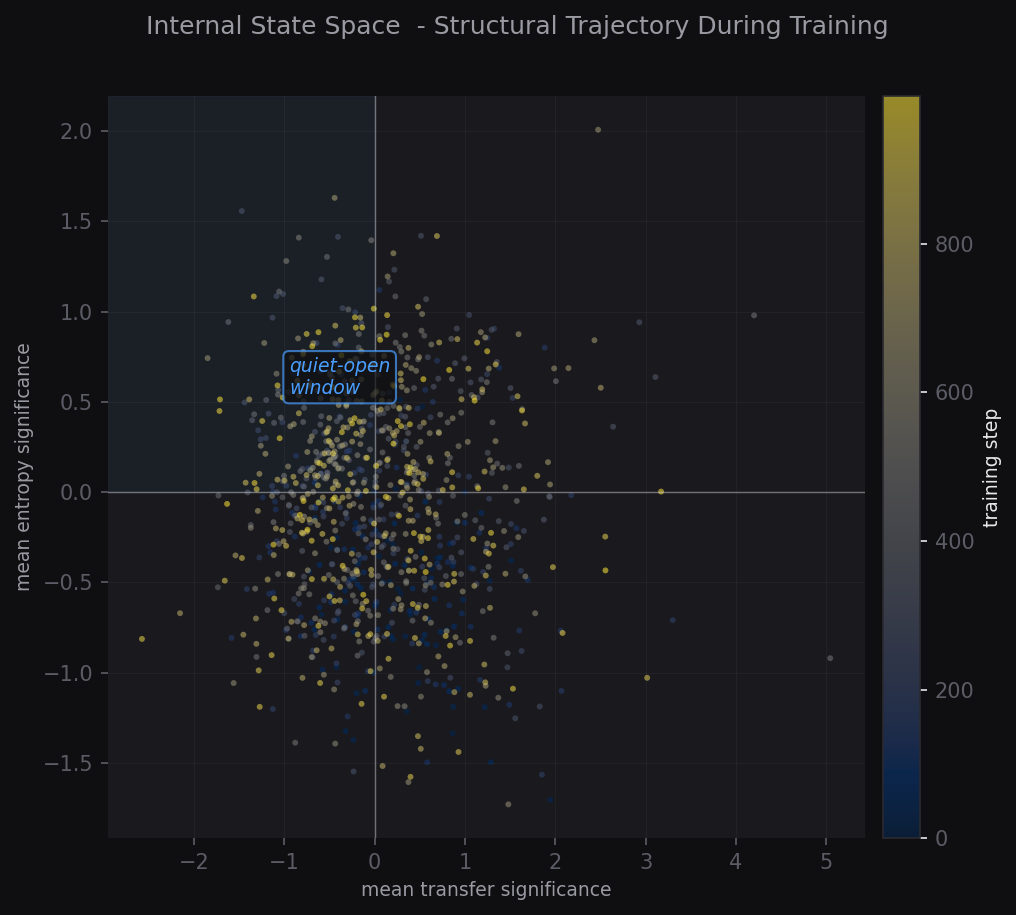
State Space
Structural trajectory, quiet-open window region highlighted.
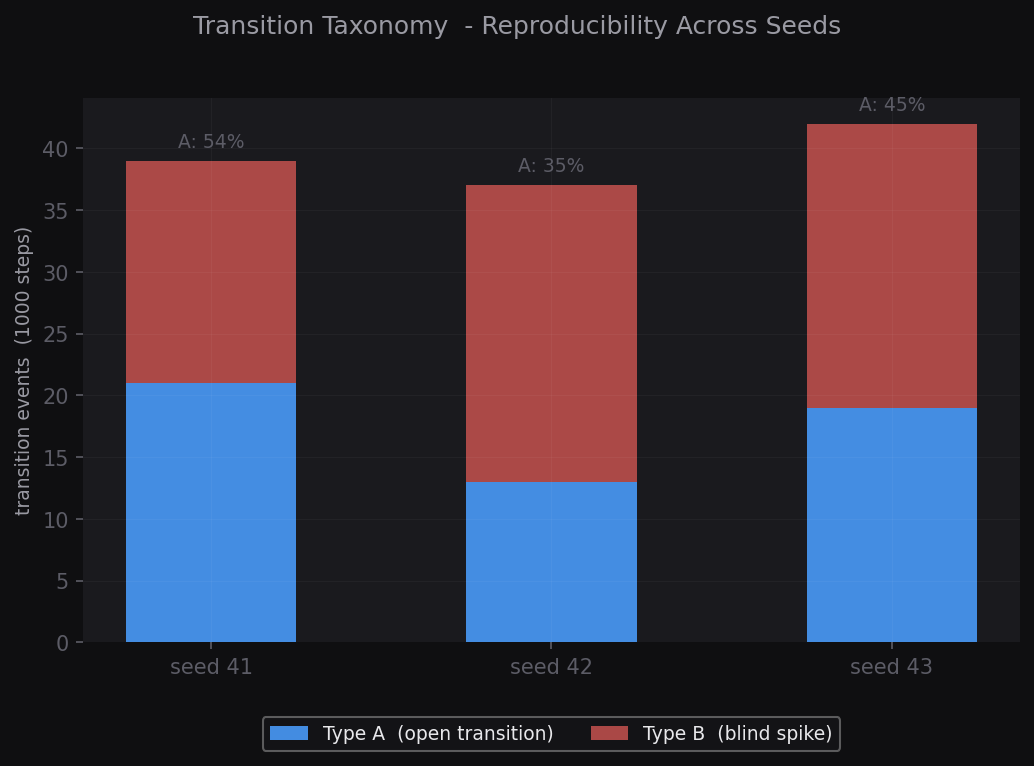
Transition Taxonomy
Type A / B events across three seeds, reproducibility confirmed.
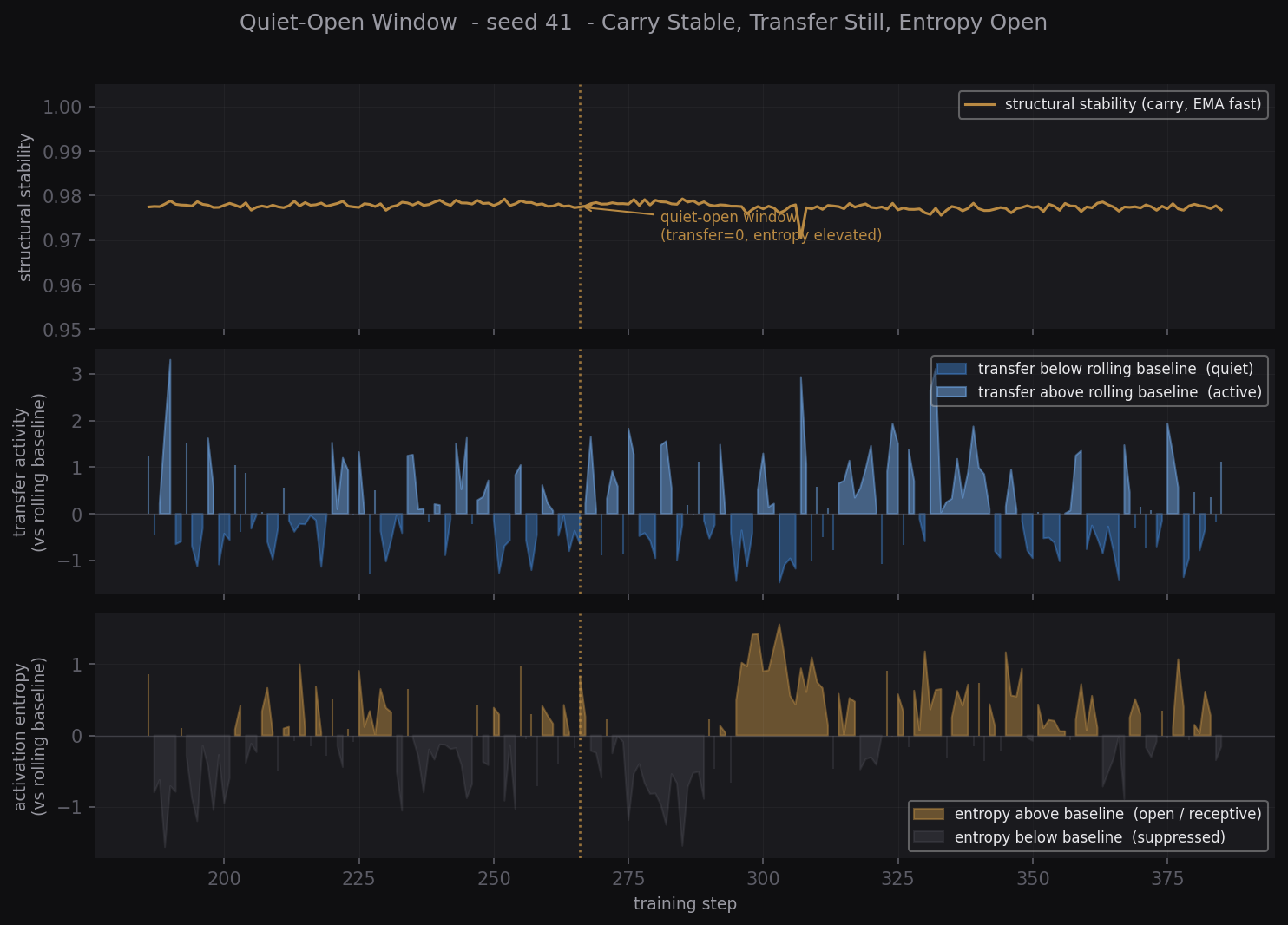
Quiet-Open Window
Carry stable, transfer still, entropy open, close-up view.
Initial evidence of structured, state-dependent dynamics during transformer training. Full intervention validation is the planned next phase.
Core Idea
The foundational principles of state-aware learning.
State (Internal Structure)
Every system exhibits an internal structure. Reading this state before updating parameters is the prerequisite for coherent adaptation.
Relation (Structural Context)
A parameter's effect depends on its role within the network. Adaptation must respect structural relationships, not just isolated values.
Selective Plasticity
Not all parameters should update simultaneously. The core challenge is distinguishing consolidated structure from regions still available for adaptation.
Endogenous Signals
Signals guiding adaptation should arise from the system's internal state, not solely from external loss functions.
AI Foundational Stack
AI systems rest on a layered foundation built over decades. We do not replace that stack, we build responsibly on top of it, targeting the layer where stability, memory, and feedback need explicit design.
Each layer in this stack was built by serious people over decades. Our work does not attempt to replace or circumvent it. We use PyTorch, standard transformer architectures, and established inference runtimes as the foundation, and ask what still needs to be built above them: observable state, structured memory, and feedback that does not silently drift.
Feedback is unavoidable
Any system carrying context over time has feedback loops. The question is whether they are observable and constrained, or silent and accumulating.
Avoiding feedback-loop amplification
We develop state-aware learning systems that separate stable evidence from repeated internal assumptions during training and adaptation.
Observability first
A system whose internal states are not readable cannot be responsibly improved. We treat observability as a prerequisite, not a feature.
No overclaim
We are not solving alignment. We are building the structural layer that makes responsible alignment work possible, state-aware, honest, measurable.